There is something quietly extraordinary about the fact that the technology underpinning every email, every streaming service, every late-night search query, was first conceived not by a visionary entrepreneur but by a defence department trying to survive a nuclear war. ARPANET history is, in many ways, the founding myth of the modern internet. And like all good origin stories, it is messier, stranger, and more human than most people realise.
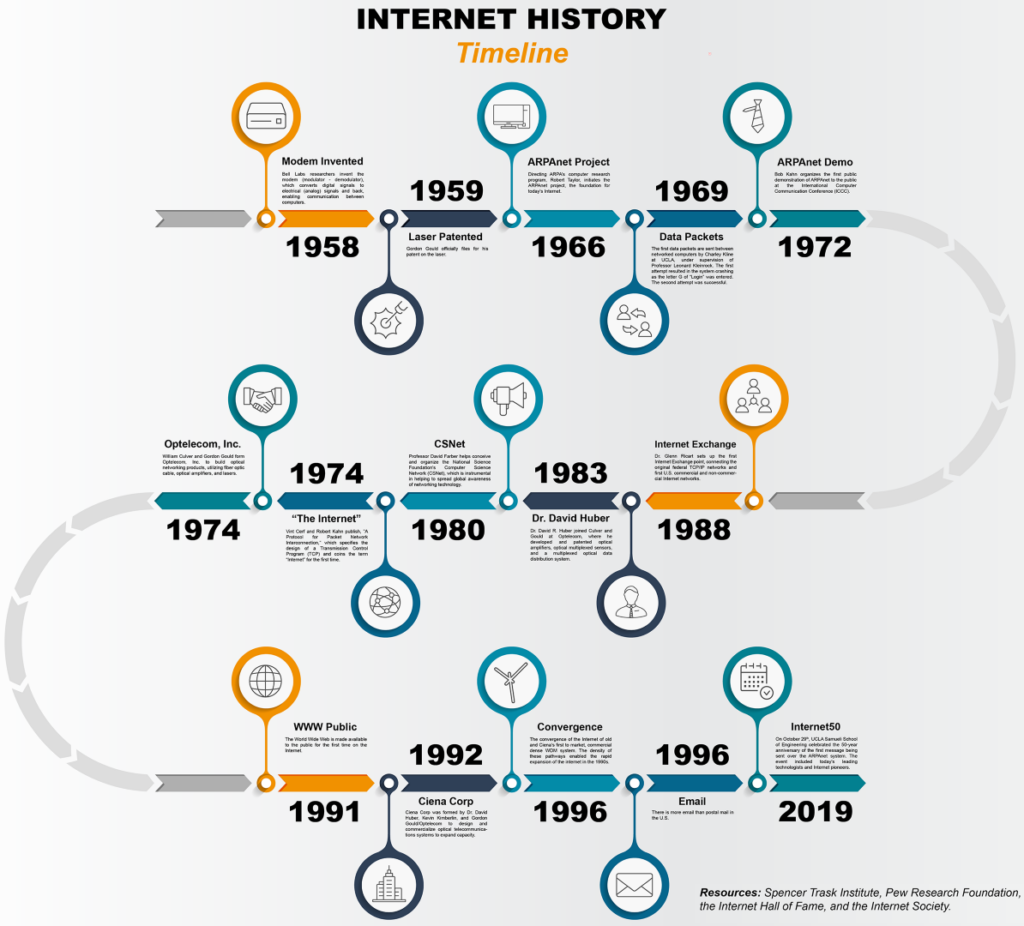
The year was 1969. The Apollo programme was dominating headlines. The Beatles were recording Abbey Road. And somewhere in a building at the University of California, Los Angeles, a team of researchers were preparing to send the first message across a brand-new experimental network funded by the United States Department of Defense’s Advanced Research Projects Agency. The network was called ARPANET. The message was supposed to say “login”. The system crashed after two letters. And so the very first word ever transmitted across what would become the internet was, appropriately enough, “lo”.

Why the Military Wanted a Survivable Network
To understand ARPANET history properly, you have to understand the paranoia of the late 1950s and early 1960s. The Cold War was at its height. The Soviet Union had launched Sputnik in 1957, demonstrating that ballistic missiles could, in theory, reach American soil within minutes. Military planners grew increasingly anxious about a single fact: America’s communications infrastructure was centralised. A nuclear strike on the right hub could silence the entire military command structure in seconds.
ARPA, established in 1958 partly in response to Sputnik, began funding research into a decentralised communications network. The key intellectual leap came from a researcher named Paul Baran at the RAND Corporation, who published a series of reports between 1960 and 1962 proposing something radical. Instead of sending a message as one continuous stream from A to B (as telephone networks did), you could break it into discrete chunks, send each chunk independently across whichever route was available, and reassemble them at the destination. He called these chunks “message blocks”. We now call them packets.
Baran’s work sat largely unread for several years. Simultaneously, and entirely independently, a British scientist named Donald Davies at the National Physical Laboratory in Teddington arrived at the same concept and coined the term we still use today: packet switching. Davies actually attempted to build a small packet-switching network at the NPL in the mid-1960s, making Britain one of the earliest proving grounds for this foundational technology. The two strands of research eventually converged, and packet switching became the conceptual backbone of ARPANET.
Building the First Nodes: 1969
ARPA awarded the contract to build the network to Bolt Beranek and Newman, a Cambridge, Massachusetts engineering firm, in 1968. The hardware they built, called Interface Message Processors (or IMPs), were essentially early routers. Each IMP connected to a host computer at a university or research institution and handled the routing of packets between nodes.
The first four nodes came online across 1969 and into 1970. UCLA was first, followed by the Stanford Research Institute, the University of California Santa Barbara, and the University of Utah. By 1971 there were fifteen nodes. By 1973, the network had crossed the Atlantic, with connections established at University College London and the Royal Radar Establishment in Norway. Britain, it is worth noting, was part of ARPANET almost from the beginning of its international expansion.

The Problem of Multiple Networks: Enter TCP/IP
By the early 1970s, ARPANET was functioning well, but a new problem had emerged. Other packet-switching networks were being built independently. ARPA’s own satellite and radio networks operated on different technical standards. These separate networks could not communicate with each other. You had islands of connectivity rather than a single sea.
The solution came from two researchers, Vint Cerf and Bob Kahn, who published a paper in 1974 describing a new suite of protocols. Their idea was elegant: create a common language that any network could speak, regardless of its underlying hardware. This language was the Transmission Control Protocol, later split into two components and known as TCP/IP. TCP handled breaking data into packets and reassembling them correctly at the destination. IP handled the addressing, ensuring each packet knew where it was going and how to get there.
TCP/IP is, without exaggeration, the foundation on which the entire modern internet rests. Every device connected to the internet today, from a server in a data centre in Slough to a mobile phone in Glasgow, communicates using the principles Cerf and Kahn laid out in 1974. The transition to TCP/IP across ARPANET was completed on 1 January 1983, a date sometimes called “Flag Day” by internet historians. From that moment, the technical architecture of the modern internet was essentially in place.
From Military Network to Academic Commons
What is fascinating about ARPANET history is how quickly the network outgrew its military origins in terms of everyday use. By the late 1970s, the most popular traffic on ARPANET was not classified defence data. It was email. Electronic mail had been introduced experimentally by Ray Tomlinson in 1971 (he is also the person responsible for choosing the @ symbol), and it spread with startling speed. Researchers were using it to share papers, argue about ideas, and arrange meetings. The network had become, in effect, a scholarly commons.
The military eventually separated its sensitive operations onto a dedicated network called MILNET in 1983. ARPANET, now largely an academic and research tool, continued operating until it was formally decommissioned in 1990. By that point, it had served its purpose entirely. The protocols it had developed, the culture of open interconnection it had established, and the physical infrastructure it had demonstrated were all inherited by the nascent public internet, which Tim Berners-Lee, working at CERN and with deep roots in the British computing tradition, would transform again with the invention of the World Wide Web in 1989.
What ARPANET Left Behind
The legacy of ARPANET history is not simply technical. It established a philosophical precedent: that a network should be open, distributed, and agnostic about the content passing through it. The end-to-end principle, as it became known, held that intelligence should sit at the edges of the network (with users and their devices) rather than in the network itself. This principle shaped the open architecture of the web and remains fiercely contested today as questions about net neutrality, content moderation, and platform power dominate public debate.
The National Physical Laboratory’s contribution through Donald Davies has been recognised more formally in recent years. The BBC covered Davies’s role in the invention of packet switching in some depth, and there is growing appreciation among historians that Britain’s contribution to the foundational architecture of the internet has been consistently underplayed.
When you send a message, stream a programme, or load a page, you are using infrastructure whose conceptual blueprint was drawn in the late 1960s by researchers who were, ostensibly, trying to survive a nuclear exchange. History rarely travels in straight lines. But few diversions have proved quite so consequential.
Frequently Asked Questions
What was ARPANET and when was it created?
ARPANET was a computer network funded by the US Department of Defense’s Advanced Research Projects Agency, first activated in 1969. It connected universities and research institutions and is widely regarded as the direct predecessor of the modern internet.
How did ARPANET lead to the invention of the internet?
ARPANET developed and proved the core technologies that underpin the internet, particularly packet switching and the TCP/IP protocols. When ARPANET was decommissioned in 1990, these protocols and the interconnected network of networks it had helped create became the foundation for the public internet.
What is packet switching and why does it matter to ARPANET history?
Packet switching is the method of breaking data into small chunks (packets), sending them independently across a network, and reassembling them at the destination. It was the key innovation that made ARPANET resilient and scalable, and remains the fundamental mechanism behind all internet communications today.
Did the UK play any role in the development of ARPANET?
Yes. British scientist Donald Davies at the National Physical Laboratory in Teddington independently invented packet switching around the same time as Paul Baran in the US, and coined the term itself. University College London was also one of the first international nodes connected to ARPANET in 1973.
When did ARPANET become the internet?
The transition was gradual. The adoption of TCP/IP on 1 January 1983 is often cited as the key technical moment. ARPANET was formally decommissioned in 1990, by which point the broader internet infrastructure it had pioneered was already carrying public traffic.