There is a particular kind of grief that comes from clicking a link and finding nothing. A blank page, a parking domain selling cheap insurance, or the stark white text of a 404 error staring back at you. For anyone who remembers the early web, link rot and dead websites are not just technical inconveniences – they are the quiet erasure of digital history, the internet’s equivalent of a library fire happening in slow motion, one broken URL at a time.

What Is Link Rot and Why Does It Matter?
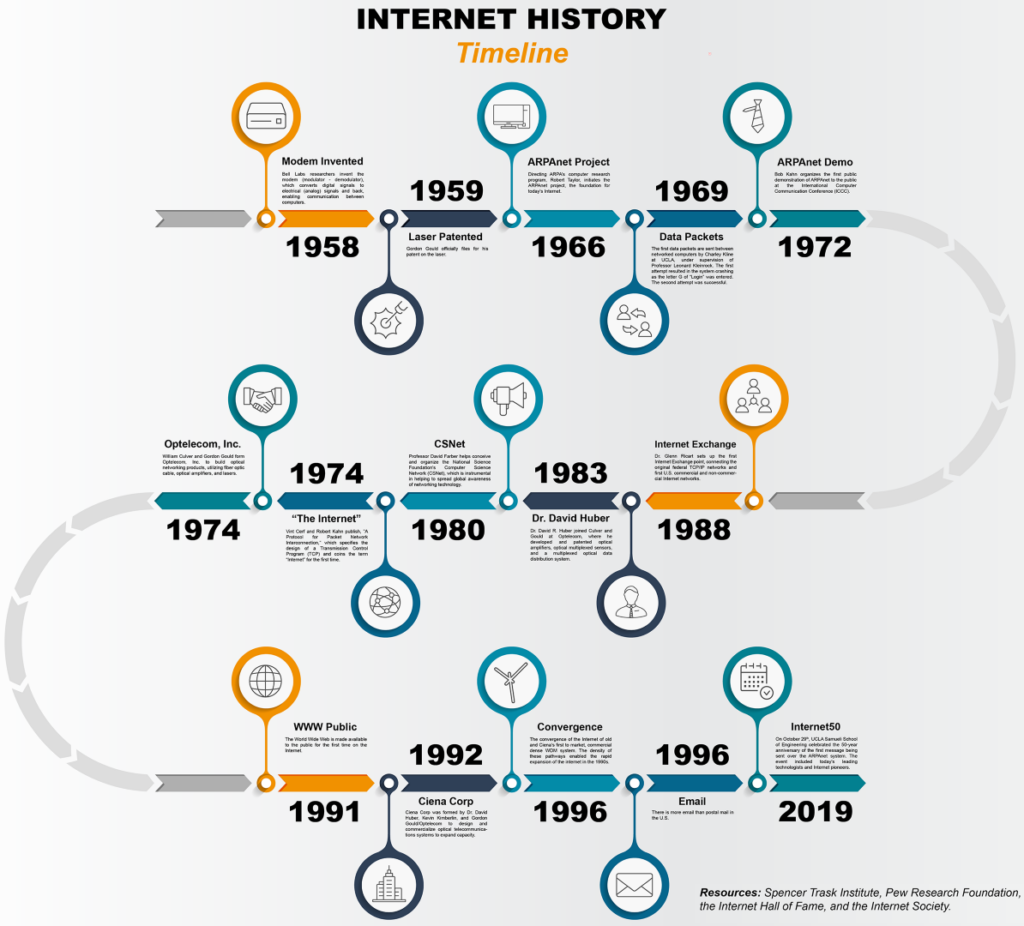
Link rot is the process by which hyperlinks gradually stop working as the pages or domains they point to disappear, move, or change. Studies have suggested that a significant proportion of URLs published even five years ago are no longer functional, and for pages from the early 1990s or early 2000s, the situation is far worse. The web was never designed with permanence in mind. Hosting bills go unpaid, companies fold, hobbyists lose interest, and servers are decommissioned. Each of these mundane events wipes out something that may have been genuinely irreplaceable.
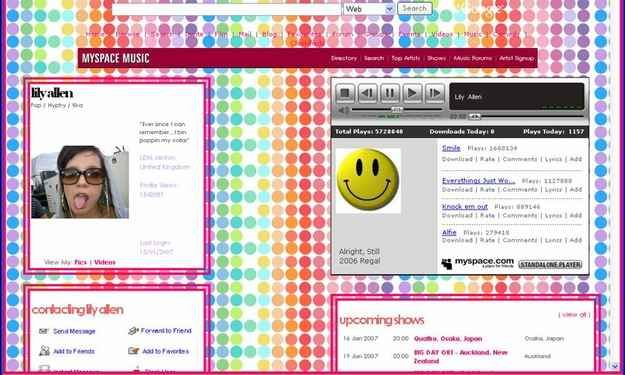
Think of the small personal homepages hosted on GeoCities – that vast neighbourhood of amateur web publishing that Yahoo shut down in 2009. Millions of pages, built with visible effort and personal pride, covering everything from fan fiction to local history to DIY electronics guides, vanished almost overnight. What remained was fragmentary at best. The loss was not just sentimental; it was cultural. Those pages documented how ordinary people used the early internet, what they cared about, and how they expressed themselves in a medium that was genuinely new.
404 Pages as Archaeological Sites
A 404 error is often treated as the end of the road, but for the digital archaeologist, it is actually a starting point. The URL itself is evidence. The domain name, the folder structure, the file name – each element tells a story about when the page was created, what kind of platform hosted it, and how the site was organised. Old URLs from early content management systems, for instance, often contain timestamps or sequential post numbers that reveal the publishing habits of whoever ran the site.
Dead domains are similarly rich with clues. When a domain expires, it sometimes gets snapped up by domain squatters, but before that happens there is often a window in which the DNS records still exist, the WHOIS history is readable, and cached versions remain accessible. Even the act of a domain changing hands leaves traces. The Internet Archive’s WHOIS database and historical DNS lookup tools can show you who owned a domain, when registration lapsed, and sometimes even the original registrant’s name or organisation.
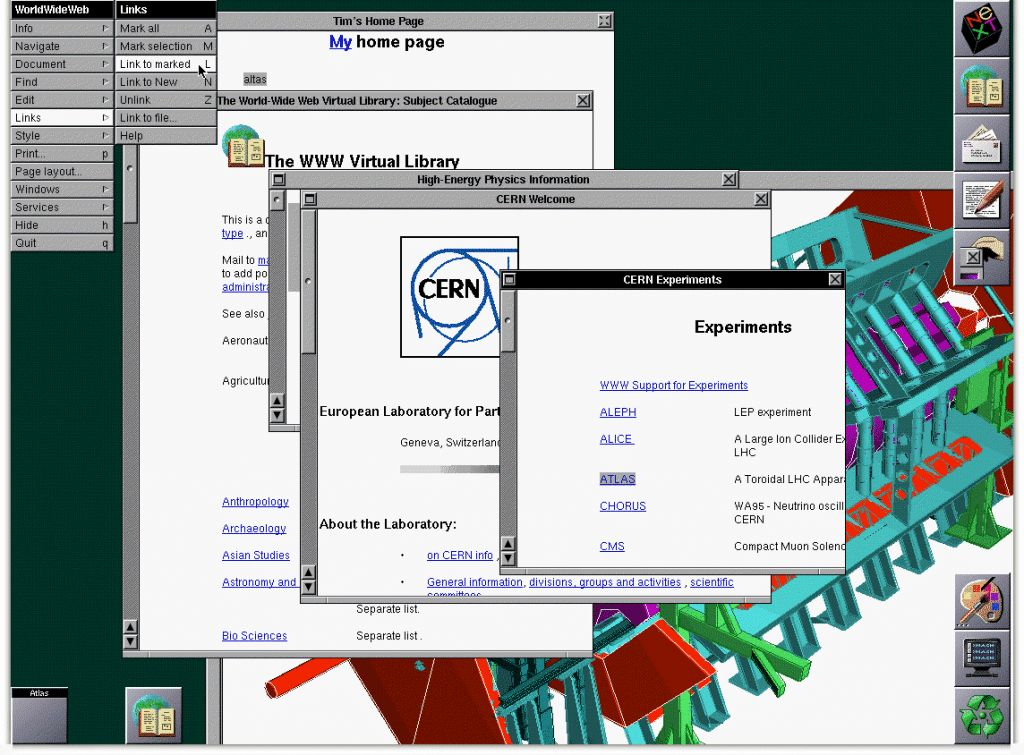
How the Wayback Machine Tries to Save Everything
The most important tool in digital preservation is the Wayback Machine, operated by the Internet Archive, a non-profit organisation based in San Francisco that has been crawling and archiving web pages since 1996. By entering a URL into the Wayback Machine, you can see a calendar of snapshots taken over the years, sometimes going back decades. For many lost sites, these snapshots are the only surviving record.
But the Wayback Machine has limitations that matter enormously when you are trying to reconstruct a dead website. Crawlers do not capture everything – dynamic content, password-protected pages, Flash animations, and embedded media often survive only partially or not at all. The archive also relies on permission systems; some website owners explicitly opted out using robots.txt files, which means their content was never captured. For the digital historian, this creates gaps that can be frustrating precisely because the absence itself is invisible. You do not always know what you are missing.
Other Tools for Excavating Vanished Pages
Beyond the Wayback Machine, a small ecosystem of tools and communities works to preserve and recover lost web content. Google’s cache, though increasingly reduced in scope, occasionally surfaces recent versions of pages that have since disappeared. Academic institutions and national libraries run their own web archives, with the British Library’s UK Web Archive being particularly valuable for British sites – it has been capturing .co.uk and .uk domains systematically since the early 2000s.
Community-led efforts have also played a vital role. The Archive Team, a volunteer group dedicated to rescuing web content before it disappears, has carried out mass archiving efforts ahead of major platform shutdowns, including the GeoCities closure. Their work, alongside projects like the TEXTFILES.COM archive maintained by Jason Scott, has saved enormous quantities of early internet culture that would otherwise be entirely gone.
For individual excavation projects, the approach tends to be methodical. Start with the Wayback Machine and note every snapshot date. Cross-reference with Google cache and Bing’s cached pages. Check if the domain ever hosted other sites before or after the one you are researching. Search for quoted text from pages you remember in case other sites quoted or copied that content. Look for mirror sites – in the early web, it was common practice to host mirrors of popular resources across multiple servers, and those mirrors sometimes survived the original.
Why So Much of the Early Web Is Simply Gone
The uncomfortable truth about link rot and dead websites is that the early web was built as if it would always exist, by people who had no real framework for understanding digital impermanence. There was no tradition of archiving equivalent to the one that existed for print. Hosting was cheap and informal. Domain registration was a novelty. Nobody thought seriously about what would happen when the money ran out or the enthusiasm faded.
This makes the surviving fragments all the more precious. A cached GeoCities page, a Wayback Machine snapshot of a now-defunct forum, an old Usenet thread preserved in Google Groups – these are primary sources in the truest sense. They are the unedited, unmediated voices of people who were present at the creation of something genuinely new. Treating them with the same seriousness that a historian would bring to a manuscript or a parish record is not overclaiming their importance. It is simply accurate.
The archaeology of the dead web rewards patience and curiosity in equal measure. Every broken link is a question worth asking.


Link rot and dead websites FAQs
What causes link rot and why do websites disappear?
Link rot happens when websites or individual pages are removed, moved to a different URL, or when their domain registration lapses and is not renewed. The most common causes include hosting costs becoming too high, companies shutting down, platform closures like the GeoCities shutdown, and individual site owners simply losing interest or passing away. Unlike physical documents, digital content has no automatic preservation mechanism, so once it is gone it is often gone permanently unless it was archived.
How do I use the Wayback Machine to find a deleted website?
Go to web.archive.org and type the full URL of the website you are looking for into the search bar. The Wayback Machine will show you a calendar view of every date on which a snapshot of that page was captured. Click on any highlighted date to view the archived version of the site as it appeared at that time. Be aware that some elements like images, embedded video, or dynamic content may not have been captured correctly, so older snapshots can sometimes appear broken or incomplete.
Is there any way to recover a website that has completely disappeared?
Full recovery is rarely possible, but partial reconstruction often is. The Wayback Machine is the best starting point, but you should also check the British Library’s UK Web Archive for British sites, search for quoted text in other pages that may have referenced the lost content, and look for mirror sites that may have copied the original. If you are trying to recover a domain’s history, WHOIS lookup tools and historical DNS records can reveal previous owners and registration dates, which sometimes leads to other archive sources.
Why didn’t the Wayback Machine capture a website I’m looking for?
Several factors can prevent the Wayback Machine from capturing a site. If the website’s robots.txt file contained instructions blocking crawlers, the Internet Archive would have respected that and not archived the content. Sites behind login walls, paywalls, or heavy dynamic scripting were also difficult to crawl accurately. Some sites were simply not popular or linked-to enough to attract the Archive’s crawler during the window when they were live. Community archiving projects like the Archive Team sometimes filled these gaps, but coverage is never complete.
What is the Archive Team and how does it help preserve the old web?
The Archive Team is a volunteer collective dedicated to rescuing digital content before major platforms shut down or delete their data. They have carried out large-scale archiving projects ahead of closures including GeoCities, Geocities-adjacent sites, and numerous social platforms. Their archived collections are often donated to the Internet Archive and made publicly accessible. Unlike automated crawlers, Archive Team volunteers can sometimes capture content that requires human navigation or login credentials, making their work particularly valuable for preserving community-built spaces on the early web.